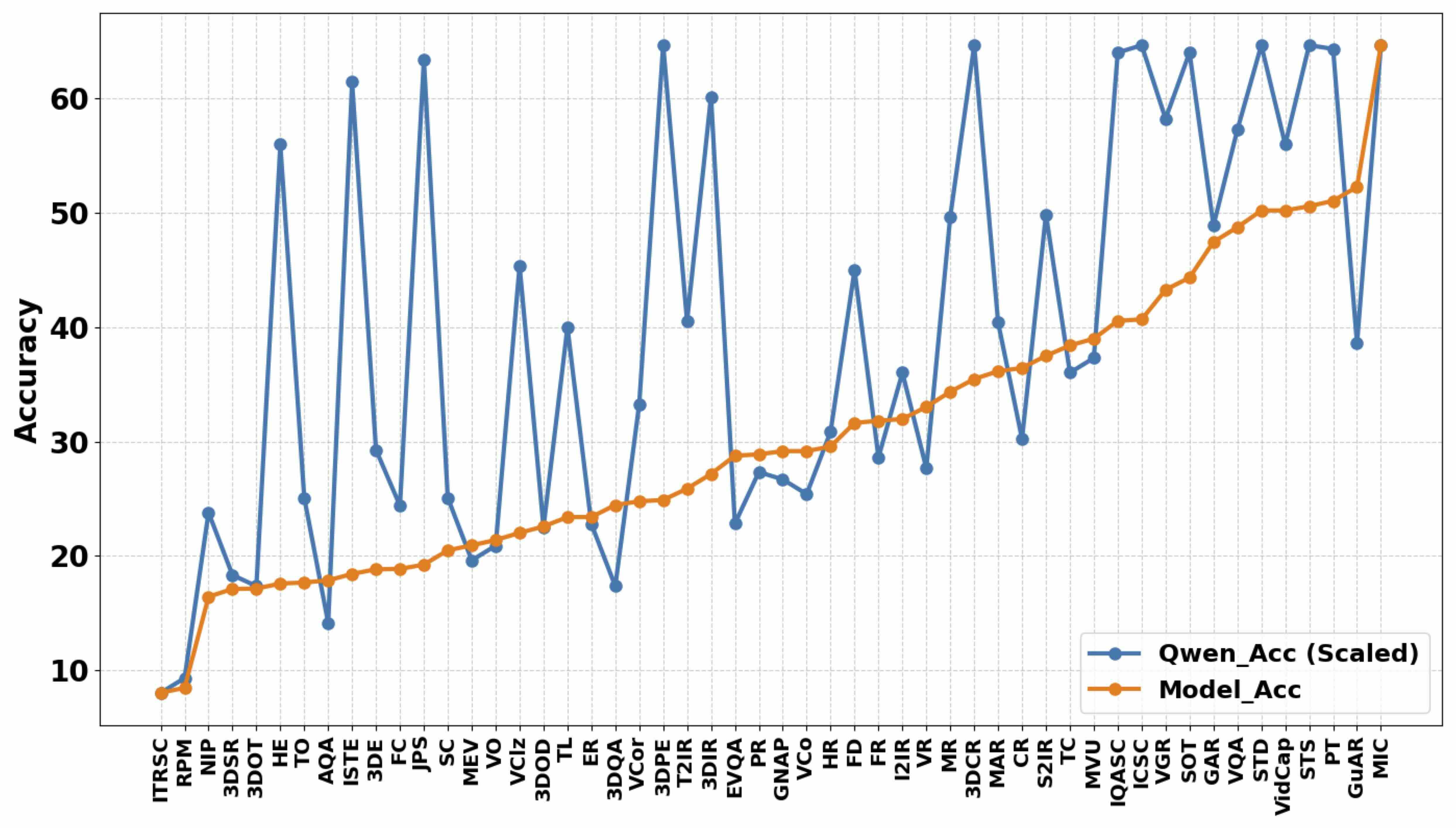

Quantitative results for 24 LVLMs across 52 tasks are summarized. Accuracy is the metric, and the Overall score is computed across all tasks. The maximum value of each task is bolded. Notice that although InternVL1.5-chat supports multiple image inputs, its training phase did not incorporate multi-image data. The full term of task abbreviation can be found in the paper.
Baseline
Adequate Multi-Image SFT LVLMs
Multi-Image input LVLMs
Single-Image input LVLMs
Closed-source LVLMs
| Model | Overall | CR | ER | FD | FC | SC | VCor | VQA | VGR | FR | HR | I2IR | MIC | PR | S2IR | STD | STS | T2IR | VR | AQA | GAR | MVU | MEV | NIP | TL | TO | VidCap |
| GuAR | GNAP | TC | VClz | VCo | VO | EVQA | HE | IQASC | ICSC | ISTE | ITRSC | MAR | MR | JPS | 3DE | 3DOD | 3DOT | 3DPE | 3DSR | 3DQA | PT | RPM | SOT | 3DCR | 3DIR | ||
| Frequency | 31.5 | 32.0 | 27.7 | 27.3 | 30.0 | 30.2 | 29.6 | 49.0 | 76.5 | 29.0 | 28.0 | 27.5 | 29.0 | 30.0 | 37.0 | 51.5 | 50.0 | 26.5 | 31.0 | 32.0 | 30.0 | 29.0 | 30.0 | 28.5 | 30.1 | 29.0 | 27.5 |
| 31.5 | 28.0 | 28.5 | 27.5 | 30.5 | 31.0 | 27.5 | 27.5 | 41.5 | 27.5 | 30.0 | 18.0 | 27.6 | 55.6 | 29.0 | 26.5 | 29.0 | 28.0 | 26.5 | 28.5 | 29.5 | 30.5 | 18.0 | 28.0 | 26.0 | 27.0 | ||
| Random | 27.4 | 19.0 | 23.0 | 22.3 | 26.4 | 24.7 | 29.1 | 45.0 | 50.0 | 23.0 | 26.0 | 24.0 | 20.0 | 24.5 | 37.5 | 51.0 | 55.0 | 27.5 | 28.0 | 28.0 | 26.5 | 24.0 | 27.5 | 23.0 | 26.9 | 24.5 | 23.0 |
| 21.0 | 12.5 | 24.0 | 27.5 | 20.5 | 27.0 | 32.0 | 31.5 | 38.5 | 27.0 | 26.0 | 14.0 | 24.6 | 50.4 | 23.5 | 25.5 | 24.5 | 22.5 | 31.0 | 23.5 | 24.5 | 25.5 | 10.5 | 22.5 | 27.0 | 27.0 | ||
| GPT-4o | 55.7 | 67.8 | 46.5 | 88.8 | 42.6 | 41.5 | 72.6 | 79.2 | 61.3 | 76.0 | 42.0 | 59.5 | 93.5 | 61.5 | 67.0 | 11.0 | 84.0 | 70.5 | 68.0 | 33.5 | 91.5 | 71.5 | 35.0 | 26.5 | 50.8 | 28.0 | 92.5 |
| 78.0 | 46.5 | 62.5 | 43.5 | 97.5 | 21.5 | 57.5 | 29.5 | 88.0 | 58.5 | 35.0 | 17.5 | 81.9 | 46.6 | 23.5 | 24.0 | 40.5 | 94.5 | 85.0 | 22.0 | 39.0 | 55.0 | 12.5 | 56.0 | 69.0 | 49.0 | ||
| Gemini1.5 | 53.4 | 71.0 | 31.8 | 73.5 | 24.3 | 34.9 | 47.3 | 78.8 | 61.0 | 88.0 | 80.0 | 74.0 | 89.0 | 70.5 | 81.5 | 74.0 | 80.0 | 60.5 | 68.0 | 35.5 | 88.0 | 75.0 | 25.0 | 21.0 | 45.6 | 26.5 | 84.0 |
| 93.0 | 39.5 | 59.0 | 30.0 | 60.0 | 43.5 | 53.5 | 22.5 | 91.0 | 64.5 | 24.0 | 13.0 | 68.8 | 51.1 | 34.5 | 20.0 | 32.0 | 48.5 | 37.5 | 28.5 | 35.5 | 66.5 | 13.0 | 61.0 | 55.0 | 43.0 | ||
| Claude3.5 | 53.4 | 70.2 | 38.5 | 76.6 | 31.3 | 34.9 | 57.0 | 77.8 | 54.5 | 92.0 | 79.0 | 62.0 | 85.5 | 77.5 | 68.0 | 80.0 | 57.5 | 65.5 | 79.0 | 26.0 | 80.5 | 75.0 | 33.5 | 10.5 | 43.5 | 23.0 | 91.0 |
| 88.5 | 55.0 | 56.0 | 26.5 | 67.5 | 38.5 | 53.5 | 23.0 | 78.5 | 52.0 | 32.0 | 4.0 | 64.8 | 42.1 | 31.5 | 23.5 | 41.0 | 32.0 | 99.5 | 21.5 | 28.5 | 78.5 | 10.5 | 67.5 | 53.5 | 36.5 | ||
| Gemini1.0 | 40.2 | 63.2 | 26.5 | 36.6 | 27.5 | 28.3 | 30.3 | 60.8 | 71.0 | 25.0 | 24.5 | 28.0 | 84.0 | 21.0 | 44.0 | 71.0 | 48.0 | 27.0 | 31.5 | 34.5 | 89.0 | 73.5 | 29.0 | 21.5 | 37.3 | 23.5 | 90.0 |
| 87.0 | 35.5 | 62.5 | 24.5 | 42.0 | 23.0 | 45.5 | 17.0 | 53.0 | 55.0 | 22.5 | 16.0 | 71.9 | 43.6 | 28.0 | 22.0 | 28.0 | 36.0 | 7.0 | 24.5 | 39.0 | 17.0 | 12.0 | 47.0 | 53.0 | 33.5 | ||
| ByteVideoLLM | 51.7 | 67.5 | 39.8 | 75.3 | 20.5 | 28.9 | 29.3 | 86.3 | 71.3 | 81.5 | 50.5 | 78.0 | 94.0 | 84.0 | 70.5 | 17.5 | 76.5 | 47.0 | 77.5 | 22.5 | 77.0 | 76.5 | 46.5 | 22.0 | 36.8 | 27.5 | 93.5 |
| 72.0 | 37.5 | 53.5 | 23.0 | 64.0 | 23.5 | 68.0 | 23.0 | 62.0 | 73.0 | 23.5 | 18.0 | 76.9 | 48.1 | 25.5 | 26.5 | 42.5 | 51.5 | 55.0 | 27.0 | 52.5 | 46.5 | 12.5 | 73.0 | 50.5 | 36.0 | ||
| Mantis | 45.6 | 61.5 | 31.8 | 57.0 | 24.3 | 28.1 | 30.9 | 59.8 | 65.2 | 66.5 | 54.0 | 63.5 | 71.0 | 57.5 | 64.5 | 96.0 | 65.5 | 46.5 | 70.5 | 17.5 | 81.0 | 58.5 | 28.5 | 26.0 | 23.8 | 27.0 | 85.0 |
| 73.5 | 34.0 | 51.5 | 31.0 | 14.0 | 20.0 | 54.5 | 23.0 | 66.0 | 48.0 | 23.5 | 13.0 | 71.4 | 47.4 | 27.5 | 23.5 | 24.0 | 26.0 | 22.5 | 25.0 | 50.5 | 76.0 | 13.5 | 50.0 | 59.0 | 40.5 | ||
| Llava-interleave | 32.4 | 29.5 | 24.8 | 26.3 | 23.2 | 26.4 | 25.1 | 48.8 | 49.8 | 23.5 | 25.0 | 28.0 | 57.0 | 21.5 | 33.0 | 63.5 | 54.5 | 25.0 | 26.0 | 24.0 | 27.0 | 49.5 | 29.0 | 23.0 | 25.4 | 27.5 | 32.5 |
| 43.0 | 34.0 | 49.0 | 29.5 | 32.0 | 26.0 | 30.0 | 21.5 | 42.0 | 47.5 | 22.5 | 14.0 | 23.6 | 32.3 | 17.5 | 28.5 | 23.0 | 17.5 | 3.0 | 31.0 | 36.0 | 79.0 | 15.0 | 60.5 | 34.5 | 42.5 | ||
| InternVL2 | 50.3 | 77.8 | 41.5 | 62.8 | 24.6 | 25.3 | 35.3 | 82.5 | 59.8 | 93.5 | 47.0 | 85.5 | 92.5 | 82.0 | 73.0 | 19.0 | 77.0 | 54.5 | 83.5 | 22.0 | 86.5 | 68.5 | 33.0 | 20.5 | 26.9 | 25.0 | 88.0 |
| 91.5 | 40.5 | 52.0 | 25.5 | 78.0 | 35.0 | 63.0 | 28.5 | 77.5 | 41.5 | 26.0 | 20.0 | 78.4 | 55.6 | 27.5 | 25.5 | 28.0 | 20.0 | 26.0 | 41.0 | 43.0 | 48.5 | 13.5 | 59.5 | 51.5 | 31.0 | ||
| InternVL1.5-chat | 37.4 | 63.7 | 31.0 | 22.6 | 20.3 | 16.3 | 28.3 | 63.2 | 38.5 | 21.0 | 28.0 | 26.5 | 82.5 | 20.5 | 31.5 | 6.0 | 45.5 | 26.5 | 29.5 | 29.5 | 85.0 | 65.0 | 32.0 | 23.5 | 29.0 | 18.5 | 89.0 |
| 90.5 | 35.5 | 56.5 | 23.5 | 31.0 | 24.5 | 53.0 | 26.0 | 40.0 | 49.0 | 25.5 | 15.5 | 59.3 | 43.6 | 19.5 | 22.5 | 23.5 | 15.0 | 33.5 | 28.0 | 39.0 | 71.0 | 9.5 | 46.5 | 50.5 | 39.5 | ||
| idefics2-8b | 27.8 | 28.0 | 25.8 | 26.4 | 26.7 | 24.6 | 28.6 | 58.5 | 30.8 | 3.5 | 9.5 | 4.0 | 82.0 | 5.0 | 27.5 | 98.5 | 70.5 | 12.5 | 7.0 | 16.0 | 24.5 | 12.0 | 19.0 | 23.5 | 22.3 | 18.0 | 19.5 |
| 23.5 | 22.5 | 21.0 | 26.5 | 21.5 | 22.5 | 14.5 | 21.5 | 31.0 | 50.5 | 25.5 | 13.5 | 15.1 | 55.6 | 27.5 | 26.0 | 21.5 | 9.0 | 21.5 | 23.0 | 11.5 | 61.0 | 18.0 | 52.5 | 44.5 | 40.5 | ||
| deepseek-vl-7b | 24.6 | 2.2 | 22.2 | 29.1 | 23.3 | 28.2 | 29.0 | 49.0 | 65.5 | 20.5 | 25.0 | 25.5 | 72.5 | 21.0 | 30.5 | 65.0 | 54.5 | 25.5 | 31.0 | 0.0 | 6.0 | 0.0 | 0.0 | 27.5 | 31.1 | 15.5 | 2.0 |
| 10.0 | 14.0 | 5.5 | 17.0 | 30.5 | 21.5 | 0.0 | 23.0 | 45.5 | 42.0 | 24.5 | 0.0 | 2.0 | 44.4 | 20.5 | 24.5 | 24.5 | 0.0 | 7.5 | 0.5 | 1.5 | 78.0 | 0.5 | 62.5 | 40.5 | 38.5 | ||
| XComposer2-1.8b | 23.5 | 24.5 | 23.0 | 19.1 | 16.4 | 18.4 | 10.0 | 27.8 | 27.5 | 13.0 | 12.0 | 26.0 | 55.5 | 19.5 | 33.5 | 17.0 | 54.0 | 10.5 | 1.5 | 25.0 | 59.5 | 37.0 | 25.5 | 0.0 | 24.4 | 13.0 | 68.5 |
| 59.0 | 28.0 | 34.0 | 25.0 | 28.5 | 17.0 | 17.5 | 0.5 | 29.5 | 48.0 | 6.0 | 7.5 | 33.2 | 41.4 | 7.0 | 0.0 | 15.5 | 17.0 | 28.0 | 2.0 | 29.0 | 33.5 | 9.0 | 27.5 | 11.5 | 3.0 | ||
| deepseek-vl-1.3b | 23.2 | 1.2 | 27.5 | 21.4 | 23.1 | 26.7 | 30.0 | 45.2 | 54.8 | 20.5 | 25.0 | 25.5 | 46.0 | 21.0 | 30.5 | 89.0 | 0.0 | 23.0 | 31.0 | 0.0 | 1.0 | 2.5 | 0.0 | 23.0 | 26.4 | 20.0 | 1.0 |
| 6.5 | 13.0 | 3.5 | 11.5 | 33.0 | 20.0 | 0.5 | 25.0 | 44.5 | 38.0 | 24.0 | 1.0 | 0.0 | 55.6 | 31.0 | 26.0 | 31.0 | 0.0 | 19.5 | 0.0 | 1.5 | 66.5 | 3.0 | 61.5 | 45.5 | 29.0 | ||
| flamingov2 | 22.3 | 25.5 | 25.8 | 24.6 | 21.6 | 25.0 | 28.2 | 34.5 | 49.0 | 14.5 | 19.0 | 13.5 | 22.5 | 17.5 | 26.0 | 39.0 | 49.0 | 20.0 | 27.5 | 10.0 | 13.5 | 16.5 | 30.0 | 20.0 | 18.7 | 24.5 | 22.5 |
| 25.0 | 21.5 | 25.5 | 25.0 | 14.5 | 13.5 | 15.5 | 27.5 | 4.0 | 25.5 | 23.0 | 7.0 | 22.1 | 3.0 | 1.5 | 26.5 | 22.0 | 35.0 | 17.0 | 28.5 | 20.5 | 23.5 | 11.5 | 31.0 | 25.0 | 23.5 | ||
| XComposer2 | 21.9 | 24.0 | 21.0 | 10.8 | 5.8 | 0.0 | 0.0 | 34.2 | 24.0 | 14.5 | 2.5 | 23.0 | 63.5 | 19.0 | 26.0 | 14.5 | 31.0 | 9.5 | 28.5 | 31.5 | 59.5 | 44.0 | 30.0 | 4.5 | 15.5 | 12.0 | 66.0 |
| 55.0 | 35.0 | 42.5 | 22.5 | 2.5 | 19.0 | 20.0 | 8.0 | 15.5 | 45.0 | 0.0 | 0.0 | 20.6 | 0.0 | 16.5 | 0.0 | 7.0 | 0.0 | 4.5 | 0.0 | 33.5 | 63.0 | 1.5 | 38.5 | 42.0 | 33.0 | ||
| qwen-chat | 15.9 | 20.5 | 2.5 | 13.3 | 2.5 | 9.9 | 5.9 | 31.2 | 23.8 | 10.5 | 19.5 | 12.5 | 41.0 | 5.5 | 13.5 | 29.5 | 45.0 | 3.0 | 12.0 | 10.0 | 52.5 | 18.5 | 16.5 | 2.5 | 3.6 | 5.5 | 47.0 |
| 29.0 | 23.0 | 18.0 | 6.0 | 6.0 | 6.0 | 32.0 | 9.0 | 13.5 | 17.0 | 15.5 | 3.5 | 40.2 | 15.8 | 16.5 | 16.5 | 22.5 | 17.5 | 13.0 | 14.5 | 14.0 | 8.0 | 3.0 | 8.5 | 1.5 | 0.5 | ||
| idefics-9b-instruct | 12.8 | 10.8 | 0.2 | 0.2 | 0.8 | 0.0 | 9.4 | 23.0 | 13.0 | 2.5 | 22.0 | 14.0 | 70.0 | 3.0 | 14.5 | 40.5 | 34.5 | 3.5 | 2.0 | 4.0 | 1.5 | 20.0 | 3.0 | 15.5 | 0.5 | 3.0 | 10.0 |
| 37.0 | 27.5 | 48.5 | 23.0 | 0.0 | 5.5 | 5.0 | 3.0 | 9.0 | 16.0 | 0.0 | 0.0 | 6.5 | 12.8 | 1.0 | 15.5 | 10.5 | 0.5 | 36.5 | 5.5 | 2.5 | 44.5 | 1.5 | 35.0 | 0.0 | 0.0 | ||
| qwen-base | 5.2 | 9.2 | 0.5 | 5.7 | 5.8 | 0.5 | 1.0 | 5.0 | 4.5 | 0.0 | 1.0 | 0.0 | 20.5 | 0.0 | 2.5 | 1.0 | 43.0 | 1.0 | 0.0 | 0.0 | 4.5 | 8.5 | 0.5 | 0.0 | 0.0 | 0.0 | 7.5 |
| 24.5 | 8.0 | 29.5 | 5.0 | 5.5 | 6.5 | 2.0 | 2.0 | 8.5 | 11.5 | 0.0 | 0.0 | 0.5 | 5.3 | 0.0 | 0.5 | 7.0 | 0.0 | 21.5 | 0.0 | 5.5 | 2.5 | 0.0 | 0.5 | 0.0 | 0.0 | ||
| glm-4v-9b | 27.0 | 32.8 | 16.0 | 31.8 | 8.7 | 9.0 | 4.7 | 59.0 | 55.8 | 31.0 | 7.5 | 19.5 | 82.0 | 23.5 | 24.5 | 81.0 | 67.0 | 25.0 | 30.0 | 7.0 | 59.5 | 53.5 | 10.5 | 5.0 | 25.9 | 10.0 | 76.0 |
| 55.5 | 19.0 | 34.0 | 5.0 | 11.5 | 14.5 | 26.0 | 11.5 | 35.5 | 41.5 | 16.0 | 6.5 | 25.1 | 29.3 | 9.0 | 14.0 | 14.5 | 7.0 | 0.5 | 5.5 | 27.0 | 35.0 | 7.5 | 26.0 | 48.5 | 23.5 | ||
| llava-next-vicuna_7b | 22.2 | 22.2 | 9.2 | 11.0 | 9.1 | 7.7 | 10.5 | 37.0 | 23.2 | 7.0 | 16.5 | 8.0 | 66.0 | 5.0 | 23.5 | 88.0 | 42.5 | 13.0 | 14.5 | 5.5 | 51.0 | 42.5 | 9.5 | 10.0 | 17.1 | 6.5 | 66.0 |
| 50.5 | 14.5 | 38.0 | 9.0 | 9.5 | 8.5 | 31.0 | 5.0 | 28.5 | 27.0 | 8.5 | 5.0 | 22.6 | 29.3 | 6.5 | 4.0 | 4.0 | 6.0 | 8.0 | 9.5 | 32.5 | 72.0 | 1.0 | 38.0 | 42.0 | 25.0 | ||
| MiniCPM-Llama3-V-2-5 | 21.6 | 41.1 | 11.8 | 13.2 | 8.7 | 5.0 | 11.3 | 47.8 | 38.5 | 7.0 | 3.0 | 6.5 | 77.0 | 7.5 | 18.5 | 41.5 | 41.5 | 10.0 | 5.0 | 0.5 | 70.5 | 51.0 | 13.5 | 4.5 | 17.6 | 5.0 | 83.5 |
| 46.0 | 24.5 | 26.0 | 4.5 | 20.5 | 12.0 | 43.0 | 0.0 | 25.0 | 44.5 | 0.0 | 1.5 | 34.2 | 38.3 | 6.0 | 8.5 | 5.5 | 9.5 | 20.0 | 4.5 | 24.5 | 14.5 | 0.5 | 22.0 | 32.5 | 15.0 | ||
| LLaVA-v1.5-7B | 19.2 | 14.1 | 4.2 | 13.7 | 5.8 | 1.9 | 6.9 | 27.3 | 35.0 | 6.5 | 12.5 | 12.5 | 53.0 | 10.0 | 25.5 | 66.5 | 43.0 | 19.0 | 3.5 | 2.5 | 23.5 | 36.5 | 12.0 | 16.5 | 6.7 | 7.0 | 28.0 |
| 24.5 | 17.5 | 40.0 | 15.0 | 21.5 | 4.0 | 26.0 | 7.5 | 26.5 | 17.5 | 5.0 | 4.5 | 25.6 | 27.1 | 8.5 | 8.0 | 4.0 | 6.0 | 6.0 | 14.5 | 29.5 | 66.0 | 2.0 | 35.0 | 34.5 | 28.5 | ||
| ShareGPT4V-7B | 18.5 | 16.4 | 5.0 | 10.8 | 6.2 | 9.0 | 2.7 | 34.2 | 28.5 | 4.5 | 10.5 | 3.5 | 57.0 | 4.0 | 12.5 | 55.5 | 44.5 | 13.5 | 5.0 | 5.0 | 26.0 | 38.0 | 14.0 | 15.5 | 10.9 | 6.0 | 25.0 |
| 26.5 | 19.0 | 42.0 | 7.5 | 14.0 | 7.5 | 31.5 | 7.0 | 29.0 | 18.0 | 5.0 | 1.5 | 28.1 | 23.3 | 9.5 | 3.0 | 7.0 | 6.0 | 2.0 | 8.0 | 27.5 | 65.5 | 0.0 | 44.0 | 36.5 | 31.0 | ||
| SharedCaptioner | 16.1 | 20.7 | 22.2 | 27.2 | 10.2 | 9.1 | 21.0 | 39.5 | 37.0 | 7.0 | 5.0 | 6.0 | 47.0 | 5.0 | 17.0 | 25.0 | 35.5 | 12.5 | 13.0 | 5.5 | 14.5 | 4.5 | 3.0 | 6.0 | 18.1 | 5.5 | 21.5 |
| 17.0 | 22.5 | 18.5 | 12.0 | 14.5 | 11.0 | 23.5 | 7.0 | 25.5 | 22.0 | 5.5 | 2.0 | 16.1 | 43.6 | 9.0 | 2.5 | 1.5 | 1.5 | 5.5 | 8.0 | 26.5 | 47.0 | 2.0 | 28.0 | 16.5 | 9.0 | ||
| Monkey-Chat | 13.7 | 8.4 | 8.0 | 5.9 | 9.2 | 6.7 | 8.1 | 23.5 | 25.3 | 4.5 | 6.0 | 1.5 | 34.5 | 2.0 | 9.0 | 40.5 | 40.5 | 12.0 | 2.5 | 6.5 | 16.5 | 14.5 | 10.0 | 12.5 | 18.1 | 6.5 | 19.5 |
| 10.0 | 8.5 | 17.0 | 8.0 | 13.0 | 7.5 | 15.5 | 7.0 | 27.5 | 17.0 | 5.5 | 3.0 | 10.6 | 22.6 | 9.0 | 5.5 | 8.0 | 6.0 | 5.5 | 7.5 | 34.5 | 51.0 | 1.5 | 17.0 | 36.0 | 8.5 |